AI
Hybrid Pruning: Thinner Sparse Networks for Fast Inference on Edge Devices
In a recent research paper, a new method has been discovered by three authors who aim to combine both coarse-grained channel and fine-grained weight pruning in order to reduce model size, computation as well as power demands with no to little loss in accuracy for enabling modern networks deployment on resource-constrained devices.
Named hybrid pruning, this model focuses on always-on security cameras and drones and helps to quickly identify the sensitivity of within and across layers of a network to the output accuracy for target multiplier accumulators (MACs) or accuracy tolerance.
From Network Pruning to Hybrid Pruning
Network Pruning is a technique used to remove some redundant weights (or channels) which don’t contribute a lot to the output of a network. The results of this technique are simple – to reduce the model size and help preventing over-fitting, eventually generating sparse (or thinner) models.
The idea of the authors of this paper, however, is to coin a new technique named Hybrid Pruning, which applies both coarse-grained channels and fine-grained weight pruning on convolutional layers for various types of neural networks.
Sensitivity-aware and statistics-aware, this technique applies weight pruning on the thinner model of drones – for further reduction in model size and computations. According to the authors:
“The basic idea is to compute layer-wise weight threshold based on the current statistical distribution of full dense weights in each layer and mask out those weights that are less than the threshold.”
There are two experiments through which the authors claim to give instant speedup of the existing hardware, and demonstrate the “coexistence of multi granularity of sparsity” which helps significantly reduce resource demands for fast interference on edge devices.
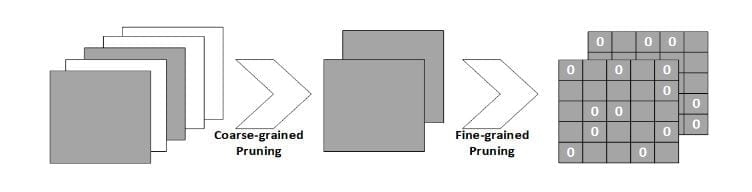
Pictorial view of our proposed hybrid pruning
The first experiment is the ResNet56 on Cifar10, which shows the result of hybrid pruning on the device, containing the channel pruning and tuning the drone to be pruned up to 75% with no significant loss in accuracy. The result is an achieved 2.4x speedup which is based on channel pruning, adding up hybrid pruning in order to boost the model to 78% sparsity, further pruned by applying weight pruning on its FC layer.
The second one, is the experiment named ResNet50 on ImageNet, which shows the output channels of another pruned drone, aiming for 2xMAC reduction based on the sensitivity test with a constraint of channels. As they observe, “similar to ResNet56, those few layers that have increased output channels (compared to previous layer) are more sensitive” which is how the authors inferred that “although network structure looks similar, it might be safe to assume that each network has different sensitivity and it’s also different across layers within a network, therefore it’s important to have a such technique that can help us to quickly identify the sensitivity of a network.”
Conclusion
Through the use of experiments, the authors introduce a model known as hybrid pruning – as one that combines both coarse-grained and fine-grained pruning in order to enable modern networks deployment on edge devices.
As they conclude:
“To the best of our knowledge, this work is the first to show that the coexistence of multi granularity of sparsity can help significantly reduce resource demands with no significant loss in accuracy. We also proposed a new fast sensitivity test technique, which helps us quickly identify the sensitivity of a network to the output accuracy for a given accuracy tolerance or target MACs.”
The technique is expected to gain mass exposure and potentially be used in order to identify the sensitivity of a network to the output accuracy of target multiplier accumulators (MACs).
Citation: Hybrid Pruning: Thinner Sparse Networks for Fast Inference on Edge Devices, Xiaofan Xu, Mi Sun Park, Cormac Brick, arXiv:1811.00482 [cs.CV] https://arxiv.org/abs/1811.00482