AI
Deep Learning Based Escape Route Recognition for Autonomous Drones in Emergency Situations
Crisis and emergency situations are definitely something that can be improved by technology. In a new paper, researchers Ricardo Buettner and Hermann Baumgartl of Aalen University, Germany, show their efficient recognition module that consists of three blocks of a depth-wise separable convolutional layer, a max-pooling layer and a batch-normalization layer and classifying different images.
With this, the researchers provide the artificial agent the ability to precisely recognize escape signs, doors and stairs for escape route planning making it suitable for embedding in operational drones and robots.
A 3-Layer System Focusing On Immediate Emergency Response
The system, as described in the paper, takes into account three consecutive levels of emergency response, including:
- Level 1: Perception of elements in current situation: All relevant elements and conditions of the environment are recognized – building the basis for all further levels of situational awareness.
- Level 2: Comprehension of current situation: The elements which have been perceived in level 1 are now processed to understand the current situation in the context of the agents’ goals.
- Level 3: Projection of future status: Based on the levels 1 and 2 possible future action of the elements are projected (action planning).
Their most important contribution is building a highly effective recognition module with an accuracy of over 99.81% which outperforms the current MCIndoor20000 benchmark. On top of that, the authors suggest a model that is 78 times smaller than the benchmark model and requires a smaller amount of computational power, making it perfect for embedding in artificial drones and robots.
“In order to substantially contribute to artificial intelligence research for crisis and emergency management and ensure strong methodological rigor, we followed the specific machine learning guidelines and conducted a comprehensive literature review,” the authors note.
A ConvNET Architecture That Includes A Layer-Based Approach
The ConvNet architecture that the authors propose includes an input, a layer 1, a layer 2 and a fully connected layer before the final output. The result is a system where every filtr is passed through a non-linearity function like ReLU (rectified linear unit) and then passed to a pooling layer.
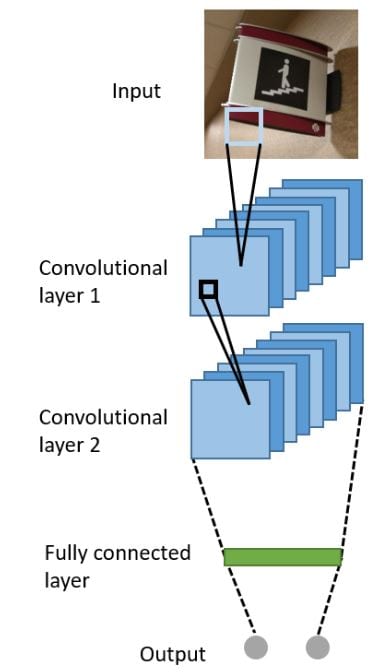
Example of a ConvNet architecture with 2 convolutional layer.
The system shows great performance but does require a reasonable amount of hardware resources and inception modules. The results of the entire evaluation data and data pre-processing shows that the model that the authors used to distinguish between the MCIndoor20000 classes consists of three blocks of depth-wise separable convolutions combined with a max pooling layer and a batch normalization layer.

Example of each image class
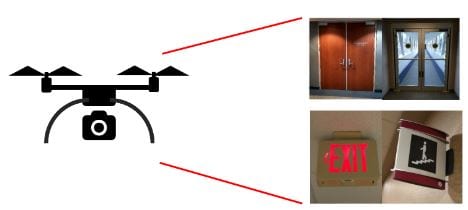
Implementation of
recognition module in a drone.
The results of their work is summed up in the following excerpt by Buettner and Baumgartl:
“We built an high-performance visual recognition module with an accuracy of over 99.81 percent which can be implemented in socially relevant software agents. The implementation of such level 1 situational awareness capabilities in software agents is an important precondition for further improvements on operable multi-agents systems as well as agent-based modeling and analyses in human decision making.”
An Efficient Module That Needs To Be Deployed In Real-World Scenarios
Condluding, the authors note that the recognition module for object detection is efficient and augments the visual recognition abilities of socially relevant multi-agent systems.
In future work, they are committed to showing re-evaluation results of their recognition module based on another very large dataset which increases external validity. In the future, the authors will present the results of the implementation of this module into an artificial drone which demonstrates a real-world scenario.
Citation: A Highly Effective Deep Learning Based Escape Route Recognition Module for Autonomous Robots in Crisis and Emergency Situations, Ricardo Buettner, Hermann Baumgart – ICT and Artificial Intelligence for Crisis and Emergency Management, http://hdl.handle.net/10125/59506